How birdSense Works
Read about how I built a AI powered bird classification system for my backyard. Built using a Raspberry Pi, Swin transformer model, aws cloud infrastructure, and this Next.js web application.
Table of Contents
Project Introduction
I decided to build BirdSense to help my dad identify all the different species of birds that visit our bird feeders in our backyard. I also wanted to build something with machine learning and computer vision, since those fields interest me and I wanted to learn more about them. What began as simple curiosity quickly evolved into a fully fledged project, involving reading research papers, training my own neural network, using a Raspberry Pi (and through that learning about Linux), and designing a website. I had no idea how challenging—but also how rewarding—it would be. I learned an immense amount about machine learning, computer vision, system architecture, and cloud infrastructure. The end result is beyond anything I could have imagined building. The model achieves roughly 92% accuracy on over 200 species of birds.
Project Goals
- Real-time bird species identification using ML
- Scalable cloud architecture
- user friendly web application to display bird classifications
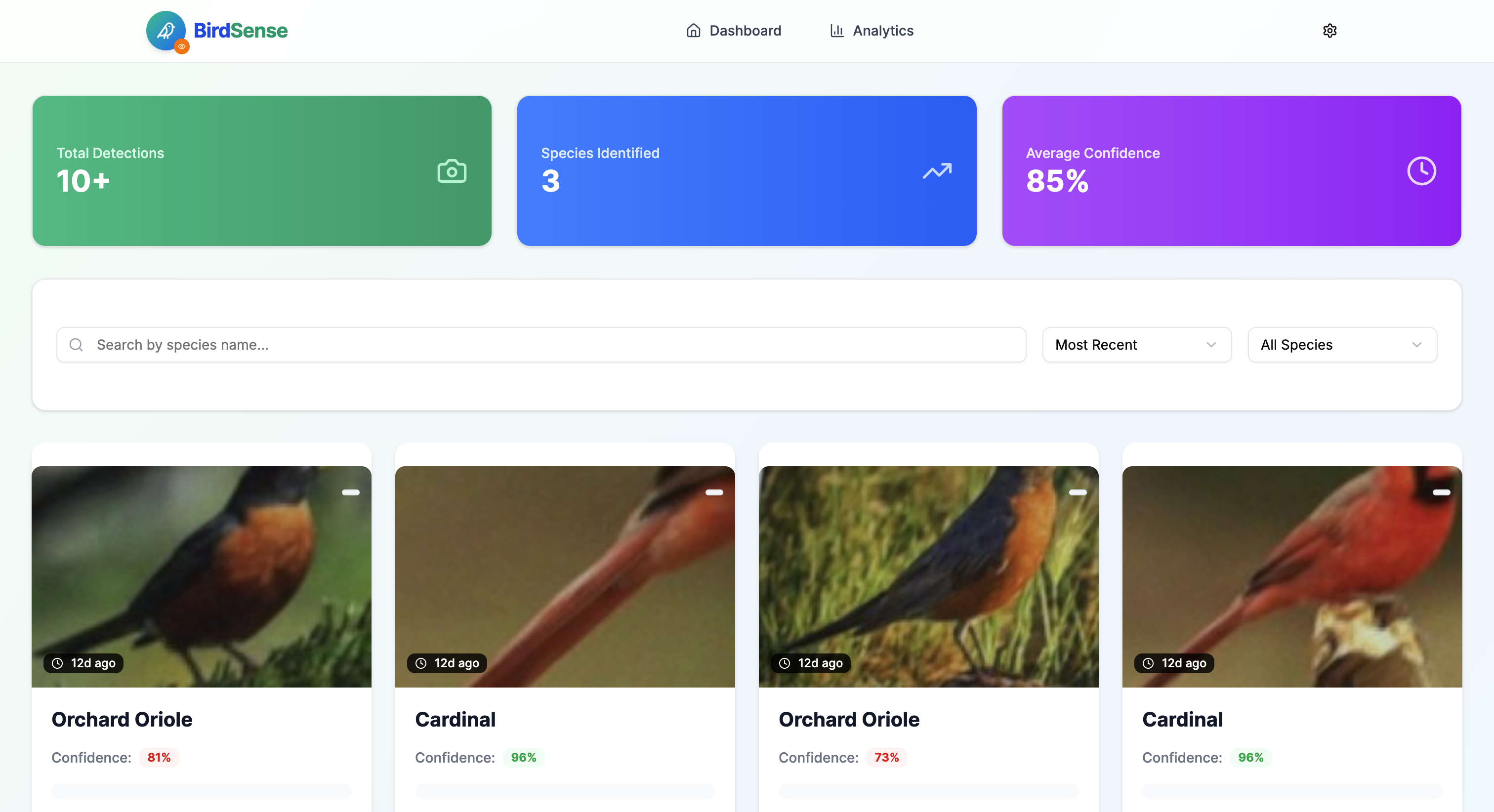
BirdSense Home page
System Architecture
The birdSense architecture implements a hybrid edge-cloud model, optimizing for both real-time performance and scalable processing. The system uses a raspberry pi, AWS Lambda for serverless functions, MongoDB Atlas for data storage, and Next.js for a responsive web experience.
Edge Processing Layer
- • Raspberry Pi with camera module
- • YOlO11 for detection
- • SwinT model for classification
- • norfair object tracking
- • upload via API
Cloud Processing Layer
- • AWS Lambda serverless functions
- • MongoDB Atlas
- • Authentication
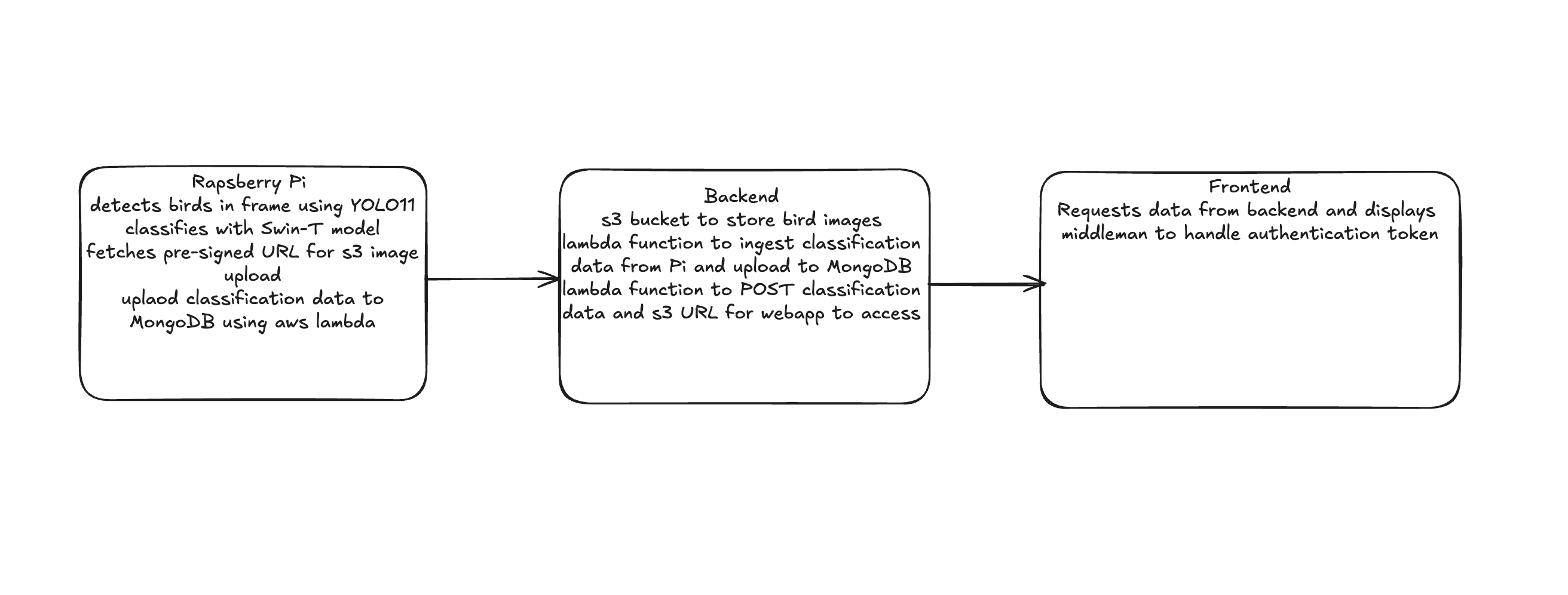
Data flow from edge device through AWS Lambda to MongoDB Atlas and Next.js frontend
Technologies Used
Hardware Setup
The edge computing component uses a Raspberry Pi 5 as the primary processing unit. A rasbperry pi camera modeule 3 is used for the camrea. Designed 3D printed housing for raspberry pi and mount for camera (waiting on 3d-printer access to print). The hardware setup focuses on reliability, performance, and weather resistance.
Hardware Components
Raspberry Pi 5 (16GB RAM)
memory for ML operations
Raspberry pi Camera module 3
12MP sensor with autofocus
Enclosure
housing and camera mount with thermal management
2.4 Ghz WiFi Connectivity
connected to internet even in backyard to allow uploading to backend

Rapberry Pi with camera In housing
Machine Learning Pipeline
To balance performance and accuract, BirdSense deploys a two-stage pipeline. First YOLOV11 detects and birds in the camera frame and draw a bounding box around them, then the cropped image is fed into the Swin transformer model for classification.
At first I wanted to use a dataset provided by Cornell lab of ornithology to train my classification model. I tried to use their NABirds dataset, this contained classification images for 400 species of birds, and was hierarchical. I quickly realized that that I was way above my head and that I needed a simplier dataset, without a hierarchical structure. I then discovered the dataset CUB-200, a much simplier dataset with 200 species of birds and over 10000 images which I ended up using for training. I split the dataset into 50% training and 50% validation according to metadata provided by the dataset.
To figure out how to train my model I read several research papers that utilized the CUB-200 dataset. I found the paper: Fine-grained Visual Classification with High-temperature Refinement and Background Suppression interesting and decided to use it as a model for my training pipeline. I initialized the SwinT backbone using the ImageNet pretrained weights. The image size was 384x384, I used an effective batch size of 32, 80 training epochs and a LR scheduler with a linear warmup followed by cosine annealing to a LR of zero. I used augmentation of random resize crop, random erasing, and the built in random augmentation method with pyTorch. the validation accuracy was logged into TensorBoard at each epoch and the best model checkpoint was saved whenever accuracy improved. The classification head combined the pre-trained backbone with a BSHead that computes top k-pooling and composite loss to achieve background suppression as specified in the paper. The model was trained using PyTorch on my Desktop computer with a 3070 Super, it took 3 whole days to run all 80 epochs. In the end the classifier achieved a top accuracy of 92% on the validation set.
Model Pipeline
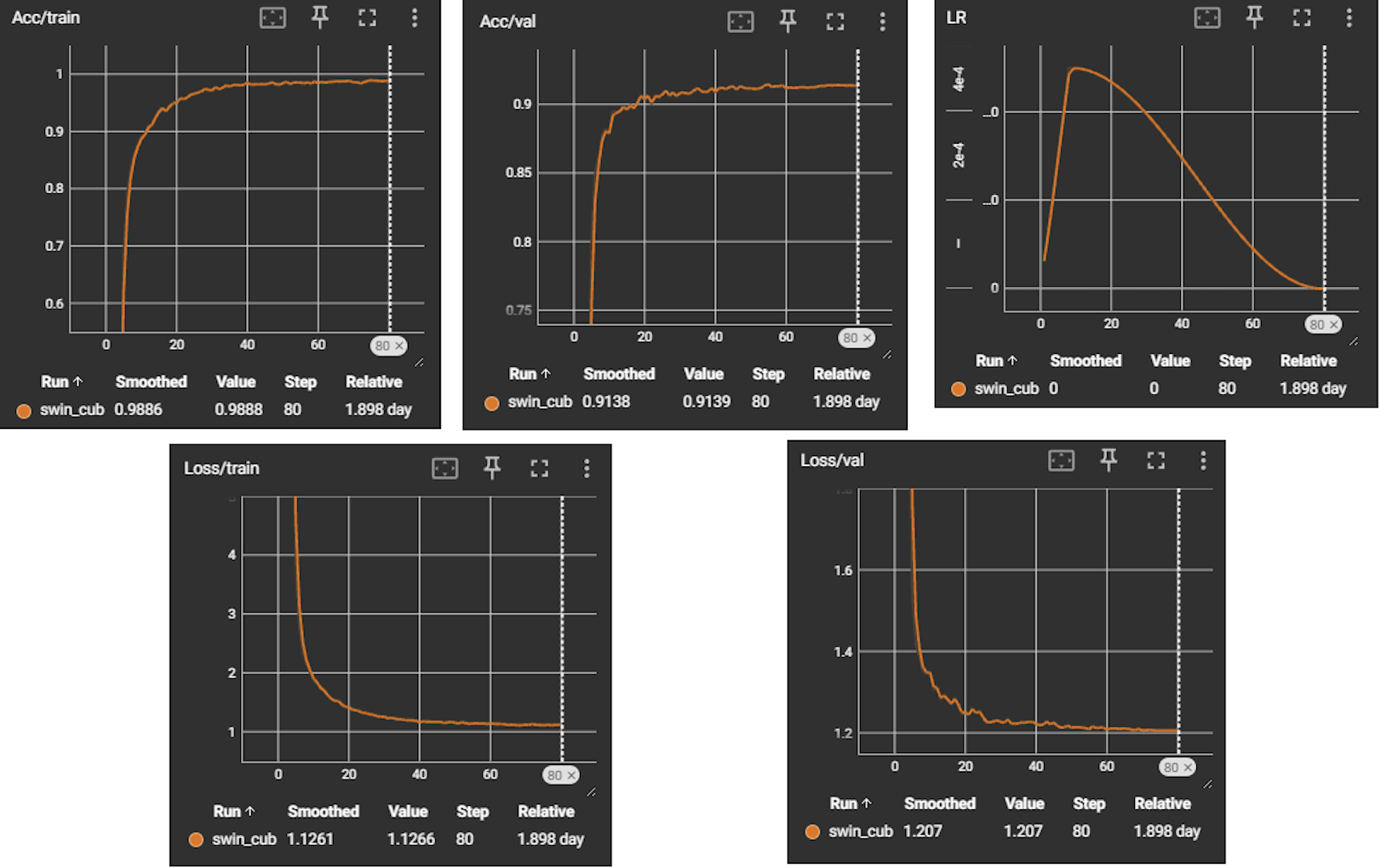
SwinT training
Model Performance Metrics
Cloud Infrastructure
I decided to use AWS and MongoDB Atlas for cloud infrastructure because of their scability, free to use tier, and because I wanter to learn how to use them. the cloud infrastructure handles my backend API and datastorage needs. I have a lambda functions that generates presigned URLs for loading and uploading images from my s3 bucket, and I have lambda functions that handle uploading and loading classification data to a from my MonogDB database. I also have a lambda function that handles my authentication. This setup is easy to maintain, extremely scalable, free, and extremely reliable.
AWS Lambda Functions
- • Generate S3 pre-signed URLs for the Pi to upload cropped bird images
- • Receive JSON payloads from the Pi containing species, confidence, timestamp, and S3 key
- • Write images into S3 via the signed URL; hand off metadata to MongoDB Atlas
MongoDB Atlas
- • Persist each classification record (species, confidence score, timestamp, S3 image key)
- • User session and device management
- • Support real-time queries for the Next.js front-end
- • Index on timestamp and species to power analytics and history lookups